Java(자료구조 및 Collections 클래스)
자료구조
데이터를 효율적으로구성하고 조작하기 위한 방법을 제공하는 클래스와 인터페이스의 모음
다양한 요구 사항에 맞게 설계되어 있으며 데이터를 삽입, 삭제, 검색, 정렬 등의 작업을 효율적으로 수행할 수 있도록 지원한다.
자바에서 제공하는 자료구조에는 배열, 리스트, 스택, 큐, 집합, 맵 등이 포함된다.
프로그램의 성능과 효율성을 향상시킨다.
정리
|
자바 컬렉션 프레임워크(Collection Framework)는 다양한 자료구조를 표준화하여 제공하는 클래스의 집합이다.
자바 컬렉션 프레임워크
|
컬랙션 객체(인터페이스)의 종류 및 계층 구조

자바는 컬렉션 인터페이스와 걸렉션 클래스로 나누어서 제공한다.
컬렉션 인터페이스
| 인터페이스 | 설명 |
| Collection | 모든 자료구조의 부모 인터페이스로서 객체의 모임을 나타낸다. |
| Set | 집합(중복된 원소를 가지지 않는)을 나타내는 자료구조 |
| List | 순서가 있는 자료구로조 중복된 원소를 가질 수 있다.(동적 배열) |
| Map | 키와 값들이 연관되어 있는 사전과 같은 자료구조 |
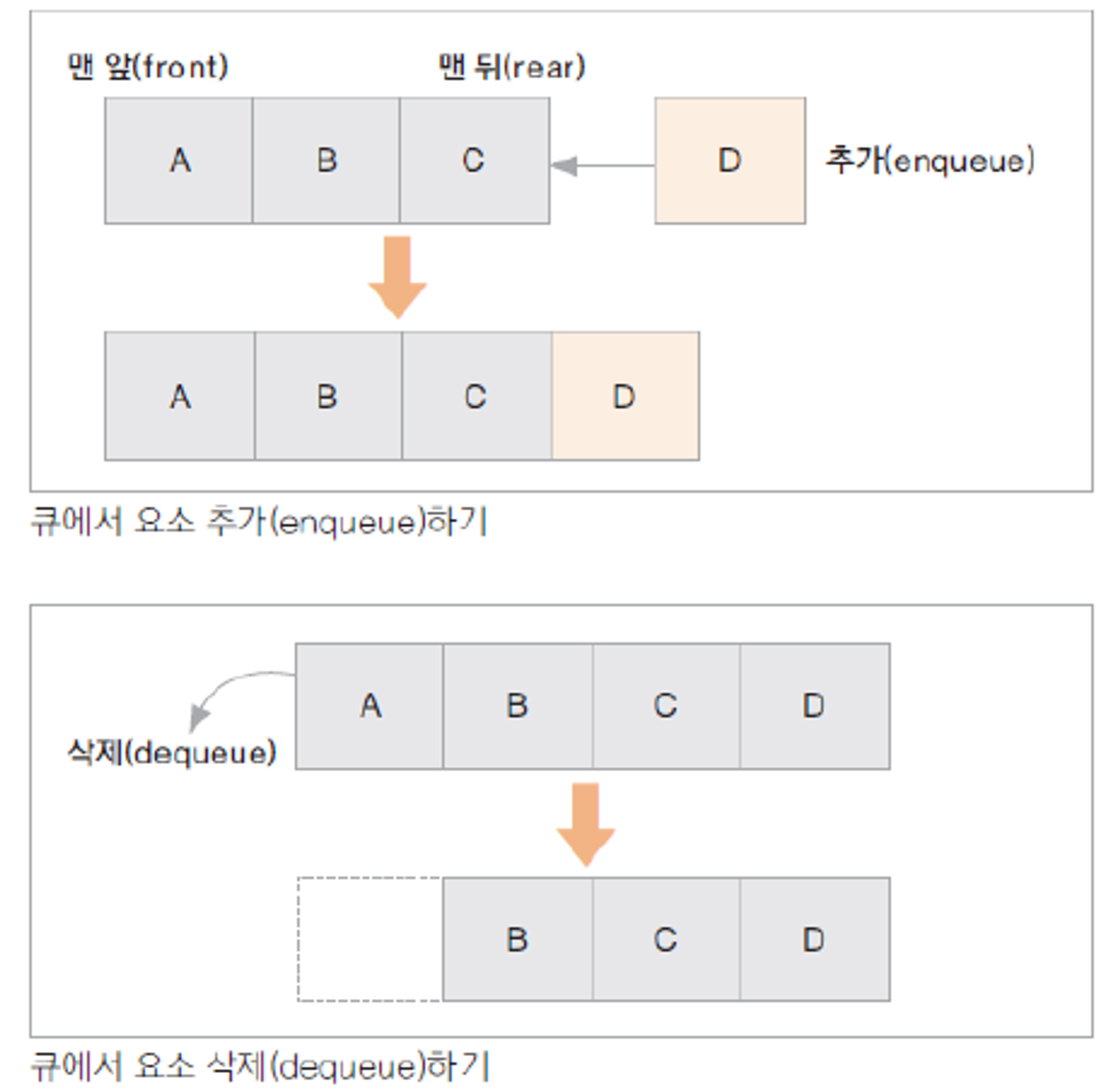
| Queue | 극장에서의 대기줄과 같이 들어온 순서대로 나가는 자료구조 |
자료구조의 유형
선형 자료구조(한 줄로 자료 관리)
배열(Array) : 정해진 크기의 메모리를 먼저 할당 받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같음
- 배열은 연속된 메모리 공간에 데이터를 저장하므로 특정 인덱스에 직접 접근하여 데이터를 읽거나 쓸 때 매우 효율적이다.
- 배열의 크기를 변경하려면 데이터를 추가하거나 삭제할 때마다 메모리의 다른 위치로 데이터를 이동시켜야 한다. 이로 인해 추가, 삭제 작업이 많은 경우에는 배열을 사용하는 것이 비효율적이다.
- 특정 위치에 새로운 데이터를 삽입하거나 삭제할 때도 데이터를 이동시켜야 하므로 작업이 번거롭다.
* 배열은 검색이 자주 일어나고 데이터가 변경되지 않는 경우에 적합하다. 추가, 삭제, 수정이 빈번하게 발생하는 경우에는 다른 자료구조를 사용하는 것이 더 효율적이다.
연결 리스트(Linked List) : 자료가 추가될 때마다 메모리를 할당 받고, 자료는 링크로 연결된다. 자료의 물리적 위치와 논리적 위치가 다를 수 있다.
* Linked list는 데이터가 추가되고 삭제하는 속도가 배열보다 빠르다.
리스트에 자료 추가하기(단순 연결 리스트)

스택(stack) : 가장 나중에 입력된 자료가 가장 먼저 출력되는 자료구조(Last In First Out; LIFO)

큐(Queue): 가장 먼저 입력된 자료가 가장 먼저 출력되는 자료구조(First In First Out; FIFO)
비선형 자료구조

부모 자식의 관계처럼 계층적 관계를 표현하는 데 사용된다.
트리는 노드(Node)로 구성되며, 하나의 노드가 다른 노드들과 연결된 구조를 가진다.
트리 구조에서는 한 노드가 최상위에 위치하며, 이를 루트(Root) 노드라고 한다.
루트 노드 아래에는 여러 개의 서브트리(Subtree)가 존재할 수 있으며, 각 서브트리도 트리 구조를 이룬다.
연결된 선은 엣지(Edge)라고 불린다. 따라서 어떤 두 노드도 정확히 하나의 엣지로만 연결된다.
트리(Tree) : 부모 노드와 자식 노드간의 연결로 이루어진 자료구조(반대로 뒤집으면 나무 형태와 비슷)
이진 트리(Binary Tree) : 각 노드가 최대 두 개의 자식을 가질 수 있는 트리이다. 즉, 0부터 2개까지의 자식 노드를 가질 수 있다. 요소가 중복되어도 상관이 없다.
이진 탐색 트리(Binary Seatch Tree, BST) : 이진 트리의 한 종류로, 각 노드에서 왼쪽 서브트리에는 노드의 값보다 작은 값들을, 오른쪽 서브크리에서는 노드의 값보다 큰 값들을 가지는 구조이다. 검색을 위해 만들어진 이진 트리로, 안에 들어가는 요소가 중복이 되면 안 된다.


이진 탐색 트리는 검색 속도가 빠른 편이다. 단, 항상 트리가 안정적으로 구현되는 것은 아니다.
편향된 이진트리를 재정렬하여 균형을 맞추는 트리를 균형 이진 탐색 트리(Balanced Binary Search Tree)라고 한다.
이진 탐색 트리를 탐색할 때, in-order Traversal(중위 순회) 방식으로 사용하면 출력되는 결과 값이 정렬되어서 나올 수 있다. (전위 순회(Pre-order), 중위 순회(In-order), 후위 순회(Post-order), 레벨 순회(Level-order))
단, 이진 탐색 트리가 아닌 일반적인 이진 트리에서는 탐색 방법에 따라 탐색 결과가 정렬되어 나온다고 보장할 수는 없다.
오름차순 정렬
순서: 왼쪽 서브트리 → 현재 노드 → 오른쪽 서브트리
방법: 1. 왼쪽 서브트리를 재귀적으로 중위 순회한다. 2. 현재 노드를 방문(데이터 처리)한다. 3. 오른쪽 서브트리를 재귀적으로 중위 순회한다.
(재귀적 : 프로그래밍에서 함수나 알고리즘이 자기 자신을 다시 호출하는 과정을 의미)
위 그림 참고 → 7 , 10, 15, 22, 23, 46, 56 (작은 값에서 큰 값으로 정렬됨)
내림차순 정렬: 중위 순회의 변형
순서: 오른쪽 서브트리 → 현재 노드 → 왼쪽 서브트리
위 그림 참고 → 56, 48, 23, 22, 15, 10, 7 (큰 값에서 작은 값으로 정렬됨)
Collections 클래스
알고리즘을 구현한 메서드들을 제공한다.
제네릭 기술을 사용하였고, 정적 메서드의 형태로 되어 있다.
알고리즘
- 정렬(Sorting)
- 섞기(Shuffling)
- 탐색(Searching)
정렬
- 데이터를 어떤 기준에 의하여 순서대로 나열하는 것이다.
- 퀵 정렬, 합병 정렬, 히프 정렬 등이 있다.
- 주로 속도가 비교적 빠르고 안정성이 보장되는 합병 정렬을 이용한다.
Collections 클래스의 sort() 메서드는 List 인터페이스를 구현하는 컬렉션에 대해 정렬을 수행한다.



리스트에 들어있는 원소가 String 타입이라면 알파벳 순서대로, Date 원소들이라면 시간적인 순서로 정렬된다.
이유는 String과 Date는 모두 Comparable 인테페이스를 구현하기 때문이다.
코드 예시)
문자열 정렬




섞기
정렬의 반대 동작
리스트에 존재하는 정렬을 파괴하여 원소들의 순서를 랜덤하게 만든다.
코드 예시)


탐색
- 리스트 안에서 원하는 원소를 찾는 것이다.
- 만약 리스트가 정렬되어 있지 않다면 처음부터 모든 원소를 방문해야 한다.(선형 탐색)
- 리스트가 정렬되어 있다면 중간에 있는 원소와 먼저 비교하는 것이 좋다.(이진 탐색)
- 중간 원소보다 찾고자 하는 원소가 크면 뒷부분에 있고, 작으면 앞부분에 있다.
Collections 클래스의 binarySearch 알고리즘은 정렬된 리스트에서 지정된 원소를 이진 탐색한다. binarySearch()는 리스트와 탐색할 원소를 받는다. (리스트는 정렬되어 있다고 가정함)
index = Collections.binarySearch(collec, element);만약 반환값이 양수면 탐색이 성공한 객체의 위치이다. 반면 반환값이 음수면 탐색이 실패한 것이다.
코드 예시)

